Risque de perturbations des services au public le samedi 26 avril 2025, en raison d'un mouvement social
Intelligence artificielle et collections de la BnF : l’exemple de l’HTR (Handwritten Text Recognition)
Les collections physiques de la BnF comptent plus de 400 000 manuscrits – dont 182 000 numérisés et disponibles dans Gallica – et 60 000 xylographes, écrits dans une centaine de langues, dont certaines très rares (tokharien B, malais, javanais, bataks…), par un nombre incalculable de scripteurs, depuis l’Antiquité jusqu’à nos jours.
S’il est possible de consulter ces manuscrits, sur place ou à distance, il n’est en revanche pas encore possible de faire des recherches à l‘intérieur des textes, comme c’est le cas pour les imprimés.
La technologie HTR
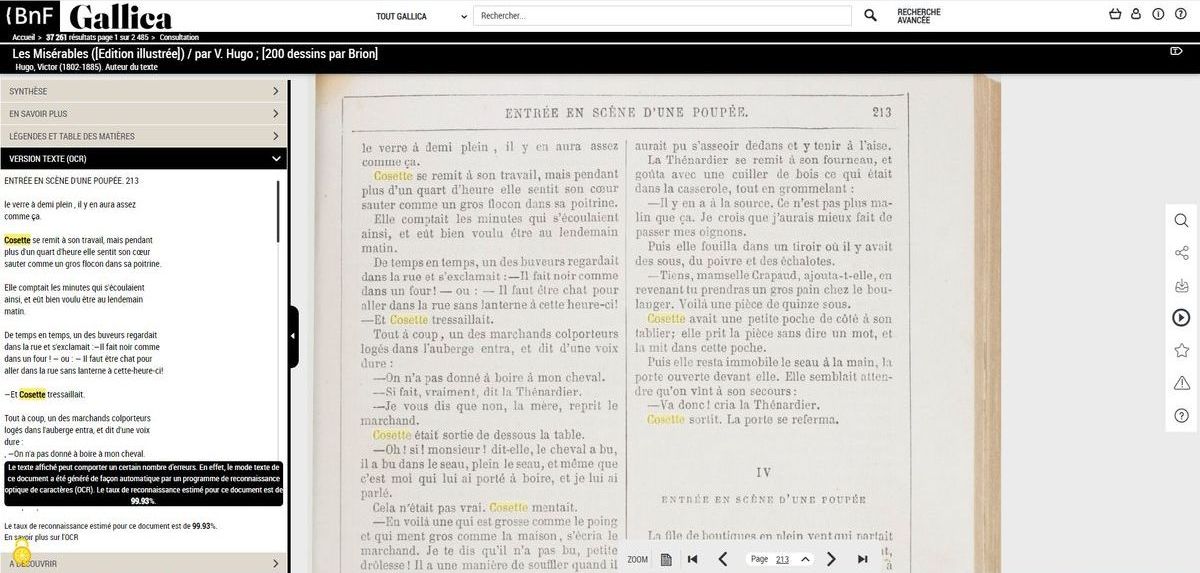
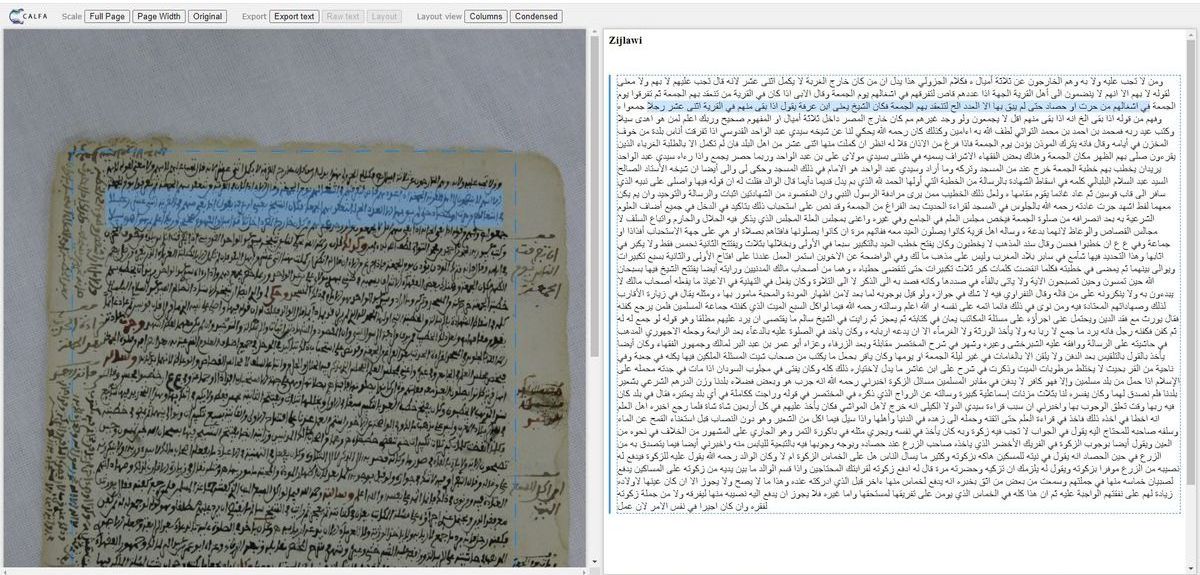
L’HTR, pour Handwritten Text Recognition, est une technologie qui vise à identifier, sur des images numériques, les signes (ou glyphes) formés par des ensembles de pixels foncés adjacents sur un fond plus clair : lettres, diacritiques, chiffres, ponctuation. Elle permet une transcription des documents manuscrits, au même titre que l’OCR (Optical Character Recognition, ou reconnaissance de caractères) pour les documents imprimés. Le formidable essor de l’intelligence artificielle (IA) – en particulier de l’apprentissage machine (deep learning) – a permis aux technologies d’HTR d’atteindre un niveau de développement permettant la mise en œuvre de programmes d’expérimentation, notamment à la BnF et dans d’autres institutions patrimoniales détentrices de fonds manuscrits.
L’HTR, comment ça marche ?
L’OCR traite de caractères séparés les uns des autres et imprimés dans des polices reconnues par les moteurs. L’HTR, lui, doit souvent composer avec des écritures cursives, très différentes les unes des autres car il y a autant d’écritures que de scripteurs.
Pour contourner cette difficulté, on entraine des modèles d’IA sur des écritures similaires, ou mieux, de la même main afin d’obtenir des transcriptions de plus en plus fidèles. Plus les modèles sont entrainés (ou « fine-tuné »), plus le taux d’erreur au caractère diminue, permettant ainsi d’accélérer considérablement les travaux de transcription ou de recherche des archivistes, des bibliothécaires ou des paléographes.
Pour cela, on peut partir de modèle dits « génériques », c’est à dire entraînés sur des corpus volumineux et très hétérogènes, qui peuvent fournir des résultats acceptables (autour de 50% de fidélité au mot), et les entrainer sur son propre corpus. Certains de ces modèles ont été rassemblés au sein d’un catalogue en ligne, HTR United, librement consultable.
Plusieurs ont été testés au DataLab :
- CREMMA pour les manuscrits en latin et en ancien français du VIIIe au XVe siècle ;
- LECTAUREP pour le français cursif contemporain ; entraîné dans le cadre d’un projet dirigé par les Archives nationales, sur des documents administratifs (1742 à 1928) ;
- Manu McFrench pour le français cursif moderne et contemporain (1600 à 2000) ;
- HTRomance
L’HTR au DataLab
Impliqué dans les travaux exploratoires en cours, le BnF DataLab a accueilli plusieurs projets d’HTR, que ce soit sur des écritures latines (HTRomance ; Gallic(orpor)a ; PaRAMHTRS), sinographiques (READ_Chinese ; ManjuGisunTranscript) l’arménien (Fonds Dulaurier) ou le syriaque.
En fonction des projets, les livrables ont permis de récupérer des modèles d’entrainement, des transcriptions, des vérités terrains et des modèles de segmentation.
L’HTR à la BnF
L’hébergement de ces projets comporte de précieux avantages pour la BnF. Le dialogue avec les chercheurs permet de juger finement de l’état de l’art, de suivre son évolution rapide, et facilite l’utilisabilité des outils et modèles produits dans le cadre de ces projets. Suite à ces expériences, un programme interne de recherche et développement (R&D) sur l’HTR, supervisé par un groupe de travail dédié, a été mis en place pour expérimenter les modèles HTR existants et fixer l’horizon de la phase d’industrialisation qui permettra de verser dans Gallica les transcriptions produites par HTR.
De plus, une chaîne de traitement va prochainement être installée sur les postes informatiques du DataLab afin de :
- tester les modèles disponibles pour déterminer quels documents sont traitables par quel modèle ;
- télécharger les modèles et les appliquer ;
- évaluer rapidement l’efficience des modèles ;
- soumettre des « vérités terrain » pour obtenir, par comparaison avec les prédictions du modèle, une mesure objective de sa précision.
Former les chercheurs
Dans le cadre de l’accueil du projet HTRomance, les équipes ont proposé une série de formation sur l’HTR, et notamment la prise en main de l’outil e-scriptorium, interface de traitement des documents manuscrits
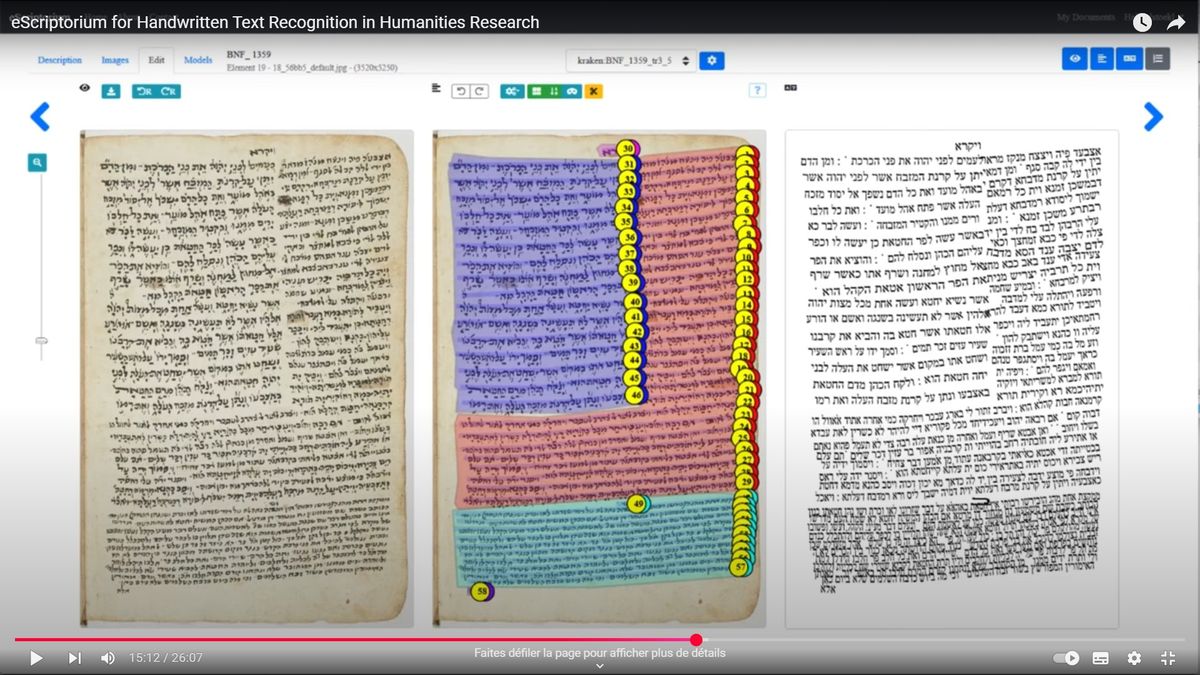
Ces formations vont être reprises en 2025 dans le cadre du projet PaRAMHTRS qui porte sur la résolution des abréviations, mais aussi de façon plus pérenne dans le cadre des formations proposées par le BnF DataLab.
Quelques définitions :
Vérité terrain : Transcription d’un document réalisée et vérifiée par un humain, à laquelle est comparée la transcription automatique réalisée par un ordinateur. Cette comparaison permet de mesurer précisément l’efficience du modèle.
Computer vision : La vision par ordinateur est un domaine de l’IA qui permet aux ordinateurs d’interpréter ce qui est représenté sur les trames en pixels des images numériques ou des vidéos. L’IA permet aux ordinateurs de « penser » ; la vision par ordinateur leur permet de « voir ». La détection d’objets, la segmentation d’images, la classification d’images, la reconnaissance de formes ou de mouvements, sont les quatre grandes catégories d’algorithmes utilisés dans ce domaine.
Glyphe : représentation graphique d’un signe typographique. Change avec la police de composition.
Écriture cursive : style d’écriture manuscrite dans lequel les lettres sont liées lors du tracé.
Modèle : En IA, un modèle est la construction algorithmique générant une déduction ou une prédiction à partir de données d’entrée. Le modèle est « entraîné » avec des données constituées ou vérifiées par des humains. Il existe en HTR des modèles de « segmentation », entrainés à reconnaitre des formes (images, marginalia, lignes…) et des modèles de reconnaissance d’écriture.
Valorisation
- GitHub du projet Dulaurier
- GitHub du projet HTRomance
- GitHub du projet Gallic(orpor)a
- GitHub du projet READChinese
- L’HTR des langues peu dotées
