Les projets en intelligence artificielle à la BnF
Gallica Images
Avec 10 millions de documents, Gallica est une des plus grandes bibliothèques numériques au monde. Les images et les documents accessibles sur notre bibliothèque numérique sont des exemples uniques de notre patrimoine commun. Cependant, la majorité des images de Gallica ne sont pas identifiées et ne sont accessibles qu’en réalisant un dépouillement manuel minutieux des documents qui les contiennent.
Le projet industriel Gallica Images a pour objectif de rendre les fonds iconographiques de Gallica, la bibliothèque numérique de la BnF et de ses partenaires, accessibles en industrialisant à grande échelle une technologie de segmentation des images (repérage à l’intérieur des livres, journaux et revues) et de caractérisation (format, couleurs, typologie, etc.) par intelligence artificielle. Le projet est une opération soutenue par l’État dans le cadre du dispositif « Numérisation du patrimoine et de l’architecture » de la filière des industries culturelles et créatives de France 2030, opérée par la Caisse des Dépôts. Il se déroule sur trois ans en partenariat avec l’Institut national d’Histoire de l’Art et la Bibliothèque Nationale et Universitaire de Strasbourg. Un marché public a été lancé et remporté par la Javaness, entreprise française spécialisée dans l’intelligence artificielle et ses technologies.

Le résultat sera une base de données publique accessible aux chercheurs, graphistes, étudiants et au public, riche de plusieurs millions d’images, d’illustrations, de menus, cartes à jouer, plans d’architecte, planches scientifiques ou animalières, partitions illustrées, etc. Les images sont en effet traitées, reconnues dans leur document d’origine et indexées avec des critères de forme, de matériaux, de technique, de sujet, parmi bien d’autres filtres. Ainsi, le trésor iconographique de l’ensemble des collections de la BnF sera désormais à portée de clic.
Durée : 2024-2026
Le projet est soutenu par France2030.
FINLAM
Le projet de recherche FINLAM (Foundation INtegrated models for Libraries Archives and Museum) vise à améliorer l’accès aux collections patrimoniales numérisées en remplaçant les méthodes actuelles limitées et aux résultats inégaux basées sur l’OCR (Optical Character Recognition) et la recherche d’entité nommées. Il est financé par l’appel à projet thématique IA « Giga-modèles pour le traitement automatique du langage naturel et des données multimodales » de l’ANR, et réunit un laboratoire de recherche, une entreprise et un établissement du patrimoine.

Il se propose de développer des modèles multimodaux (texte-image) pour l’extraction d’informations de documents numérisés ou nés numériques. En combinant la vision par ordinateur et les grands modèles de langage (LLM), ces approches seront plus polyvalentes et adaptables à différents corpus. L’objectif est de créer la nouvelle génération de systèmes d’ingénierie documentaire, capable de traiter des requêtes multimédia sur une grande diversité documents, de langues, de mises en page, de styles d’écriture et d’illustrations. Cette architecture permettra des interactions riches et facilitées avec les collections des bibliothèques, archives et musées.
Pilote et partenaires : LITIS Université de Rouen Normandie ; TEKLIA ; Bibliothèque nationale de France
Financement : ANR-23-IAS1-0007
Durée : 2023-2027
ArGiMi
En mai 2024, le projet collaboratif ArGiMi a été sélectionné dans le cadre de l’appel à projets « Communs numériques pour l’intelligence artificielle générative », lancé par Bpifrance dans le cadre du programme France 2030. Coordonné par la société Artefact, ce projet réunit des acteurs industriels de l’IA (Mistral AI, Artefact, Giskard) et deux établissements publics patrimoniaux, la BnF et l’INA, autour d’un objectif commun : créer et partager des communs numériques, dont un grand modèle de langue francophone.
La BnF jouera un rôle clé en mettant à disposition un corpus textuel de documents du domaine public, issus de sa bibliothèque numérique Gallica. Ce corpus alimentera un modèle de langue de fondation, développé par Mistral AI, qui sera ensuite affiné pour des usages spécifiques tels que la correction de textes transcrits par OCR dans Gallica et le traitement d’informations structurées.
Grâce à son implication dans ArGiMi, la BnF contribue au développement d’un modèle de langage sous licence ouverte constituant des communs numériques pour l’IA générative. Le projet permettra par ailleurs de mener une étude juridique sur l’utilisation des données patrimoniales pour l’entraînement de modèles d’IA générative. ArGIMi a débuté en janvier 2025.
Durée : 2024-2026
Le projet est soutenu par France2030.
Découvrabilité des collections
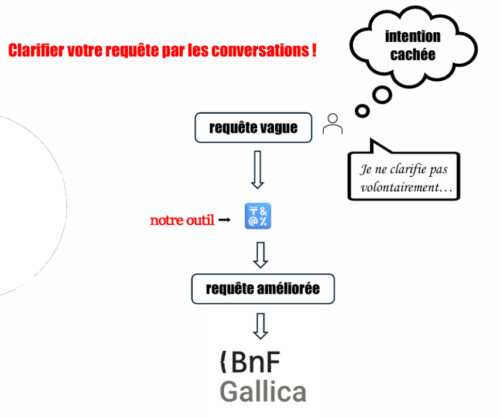
Le Sorbonne Center for Artificial Intelligence (SCAI) et la BnF financent en partenariat un projet de recherche portant sur la découvrabilité des collections numérisées. L’objectif est l’amélioration de la pertinence du moteur de recherche de Gallica par la clarification des requêtes émises par les usagers. En grande majorité, les requêtes adressées aux portails documentaires ou bibliographiques s’expriment par mots-clés, à l’aide de recherches simples ou avancées (dans le cas de Gallica, cette dernière n’étant en réalité utilisée que par 5 % des utilisateurs). Le prototype développé tente, à l’aide d’une « conversation » avec un grand modèle de langue (LLM, large language model), de clarifier certaines requêtes vagues en dévoilant l’intention de l’usager cachée derrière un mot-clé. À la fin de l’échange, une requête améliorée serait générée, conduisant à des résultats de recherche plus pertinents.
Durée : 2023-2025
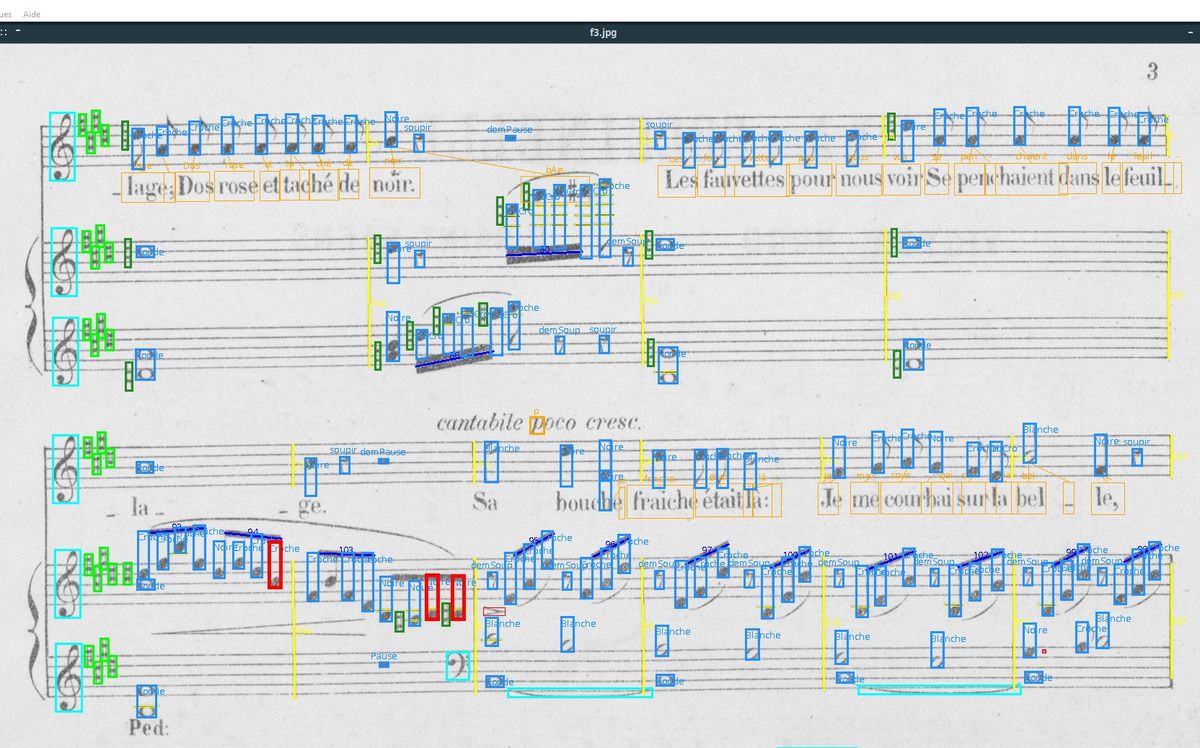
Collabscore
Les collections de partitions musicales constituent une part importante des fonds documentaires conservés par les bibliothèques patrimoniales. Elles se limitent cependant le plus souvent à une numérisation en mode image,ce qui limite les services pouvant être proposés au-delà de la seule visualisation. Le projet ANR CollabScore vise à transformer ces partitions-image en partitions éditables, offrant de bien plus grandes potentialités d’interaction, dont notamment l’écoute synchronisée avec d’autres sources. Le projet, porté par un consortium associant informaticiens, bibliothécaires et musicologues, met en œuvre des méthodes de reconnaissance optique, de correction collaborative et de gestion documentaire pour proposer de nouveaux paradigmes de numérisation et d’interaction avec les fonds musicaux patrimoniaux.
Partenaires : CNAM/CEDRIC, Irisa (Rennes), IReMus, Fondation Royaumont, université de Lille
Financement : https://anr.fr/Projet-ANR-20-CE27-0014
Durée : 2021-2025